近日,我中心有2篇论文被多媒体国际顶级会议ACM International Conference on Multimedia(简称ACM MM,CCF A类会议)录用,两篇论文分别关注人工智能-计算机视觉中的视频目标检测和人脸表情识别任务。
由我中心硕士生林丽健、博士生陈昊升以及硕士生梁俊合作完成的论文 “Dual Semantic Fusion Network for Video Object Detection”被ACM MM接收,论文框架如图1所示。该论文提出了一种基于双重语义融合的视频目标检测方法(DSFNet),用于同时在帧级别和物体实例级别融合视频中的特征,利用视频中丰富的时空信息来辅助每一帧的检测。该论文提出的方法利用深度神经网络实现,所提出的网络结构可以端到端训练。此外,该文提出了一种新的几何度量方式来减轻特征融合当中的由于噪声引起的信息失真问题。实验结果表明,该方法在视频目标检测公开数据集上达到了现有最高的精度。该论文由王菡子教授和腾讯PCG ARC的张宏伦博士、李昱博士、单瀛博士共同指导。
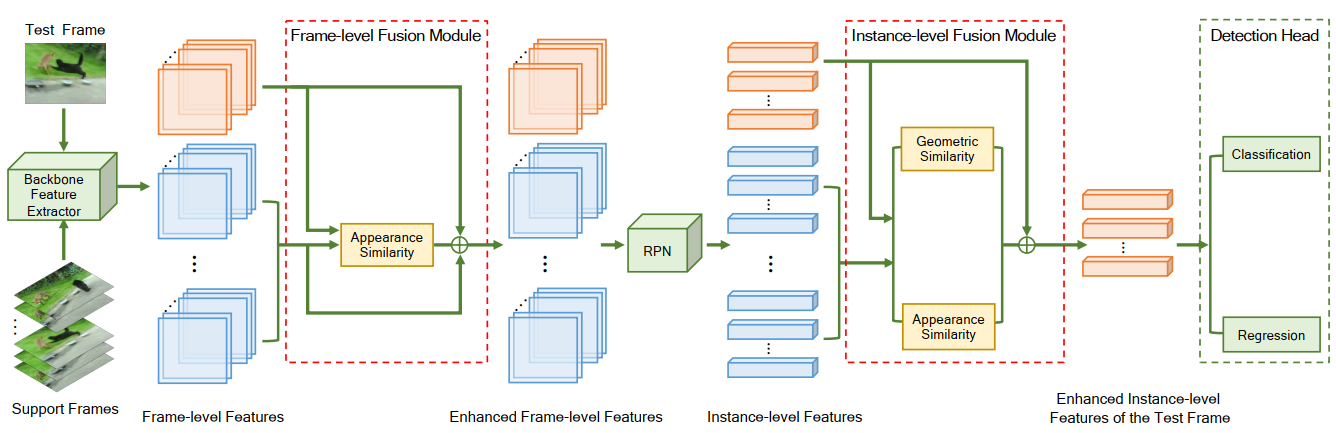
图1. 算法框架图
由我中心硕士生阮德莲完成的论文“Deep Disturbance-Disentangled Learning for Facial Expression Recognition” 被ACM MM接收,论文框架如图2所示。该文考虑到人脸表情图像受到很多因素的干扰,如身份、性别、年龄、光照、姿态等,提出一种基于干扰分离学习的方法用于表情识别任务。首先利用其它人脸数据集中的干扰标签来训练一个干扰特征提取模型,再通过对抗性迁移学习的方法来将模型特征迁移到表情识别模型中。在表情识别模型中使用多任务学习的方式将表情特征和干扰特征解耦,得到更干净的表情特征。实验结果表明,该方法在5个公开的常用数据集上都达到了优异的表情识别效果。该论文由严严副教授、王菡子教授、厦门理工学院陈思副教授和伦敦大学学院薛景浩副教授共同指导。
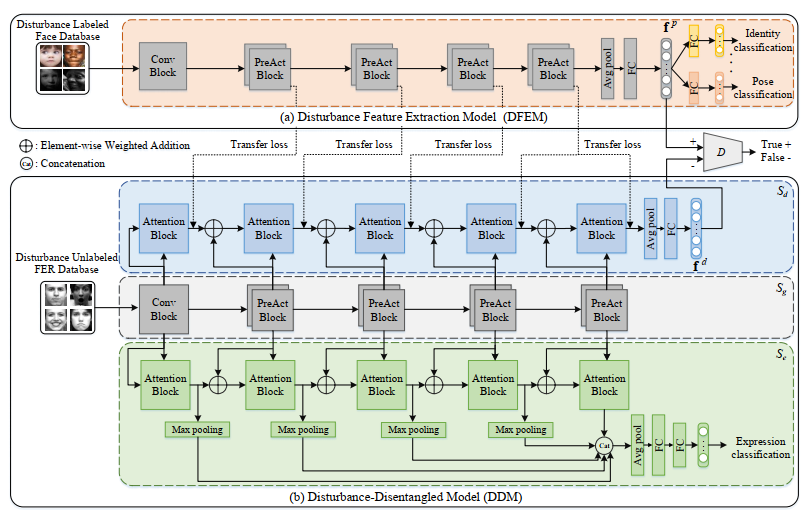
图2. 算法框架图
