近日,我中心9篇论文被第32届多媒体国际顶级会议ACM International Conference on Multimedia(简称ACM MM,CCF A类会议)录用。本届ACM MM共收到有效论文投稿4385篇,其中1149篇论文被录用,录用率为26.20%,录用论文简要介绍如下。
论文1:Semi-Supervised Visible-Infrared Person Re-Identification via Modality Unification and Confidence Guidance
作者:郑希颖(厦门大学)、张玉康(厦门大学)、卢杨(厦门大学)、王菡子*(通讯作者,厦门大学)
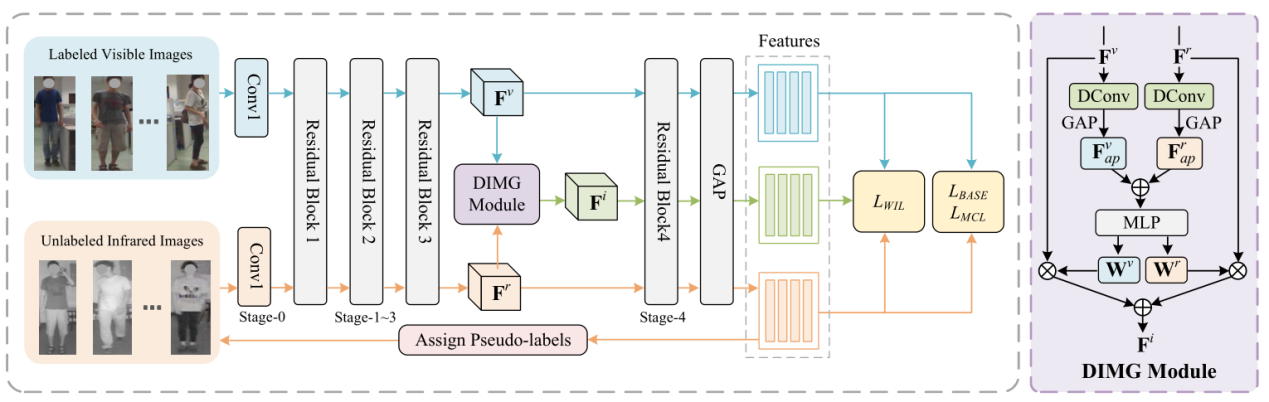
简介:本文的第一作者是厦门大学信息学院2022级硕士生郑希颖,通讯作者是王菡子教授,由张玉康博士、卢杨助理教授共同合作完成。本文提出了一种新颖的模态统一与置信引导(MUCG)的半监督学习框架,致力于解决半监督可见-红外人重识别(SSVI-ReID)任务中两个关键挑战:噪声伪标签和显著的模态差异。为了解决这些问题,我们首先引入了一个动态中间模态生成(DIMG)模块,该模块能够将标记可见光图像的知识迁移到未标记的红外图像上,从而增强伪标签的质量并缩小模态间的差距。同时,我们设计了一种加权身份损失(WIL),利用置信度加权策略降低模型对错误标签的依赖。此外,我们还开发了一种模态一致性损失(MCL),有效缩小了可见光和红外特征的分布距离,进一步促进了模态统一特征的学习。大量实验表明,MUCG在提升SSVI-ReID任务的性能方面具有显著优势,明显超越了现有的半监督方法。
论文2:Efficient Perceiving Local Details via Adaptive Spatial-Frequency Information Integration for Multi-focus Image Fusion
作者:黄婧嘉(厦门大学)、涂晓彤*(通讯作者,厦门大学)、丁兴号(厦门大学)、黄悦(厦门大学)
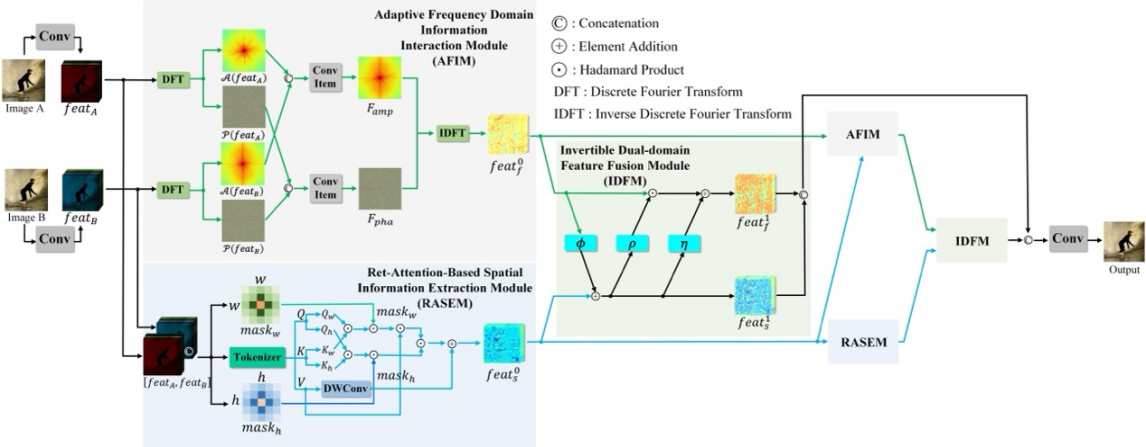
简介:本文的第一作者是信息学院2022级硕士生黄婧嘉,通讯作者是涂晓彤助理教授,由丁兴号教授、黄悦教授等合作完成。多焦点图像融合(MFIF)旨在将多个具有不同聚焦区域的图像合并成一张全聚焦图像。现有的无监督深度学习方法仅在空间域内融合图像的结构信息,忽略了在频域探索可能的潜在解决方案。本文首次尝试集成空域和频域的图像信息以实现高质量的MFIF。本文提出了一种新颖的无监督空-频双域交互MFIF网络,名为SFIMFN,它由三个关键组件组成:自适应频域信息交互模块(AFIM)、基于Ret-Attention的空间信息提取模块(RASEM)和可逆双域特征融合模块(IDFM)。具体来讲,在AFIM中,通过结合多张图像的幅值和相位信息,交互式地探索全局上下文信息。在RASEM中,通过显式设计具有2D衰减自注意机制的定制Transformer,鼓励网络捕捉重要的局部高频信息。最后,IDFM在信息无损的原则下融合空-频双域信息,生成全聚焦图像。在不同数据集上的大量实验表明,本文方法在定性和定量指标以及泛化能力上均显著优于最新的无监督方法。
论文3:Robust Pseudo-label Learning with Neighbor Relation for Unsupervised Visible-Infrared Person Re-Identification
作者:尹祥博(共同一作,厦门大学)、施江鸣(共同一作,厦门大学)、张亚超(清华大学深圳研究院)、卢杨(厦门大学)、张志忠(华东师范大学)、谢源*(通讯作者,华东师范大学)、曲延云* (通讯作者,厦门大学)
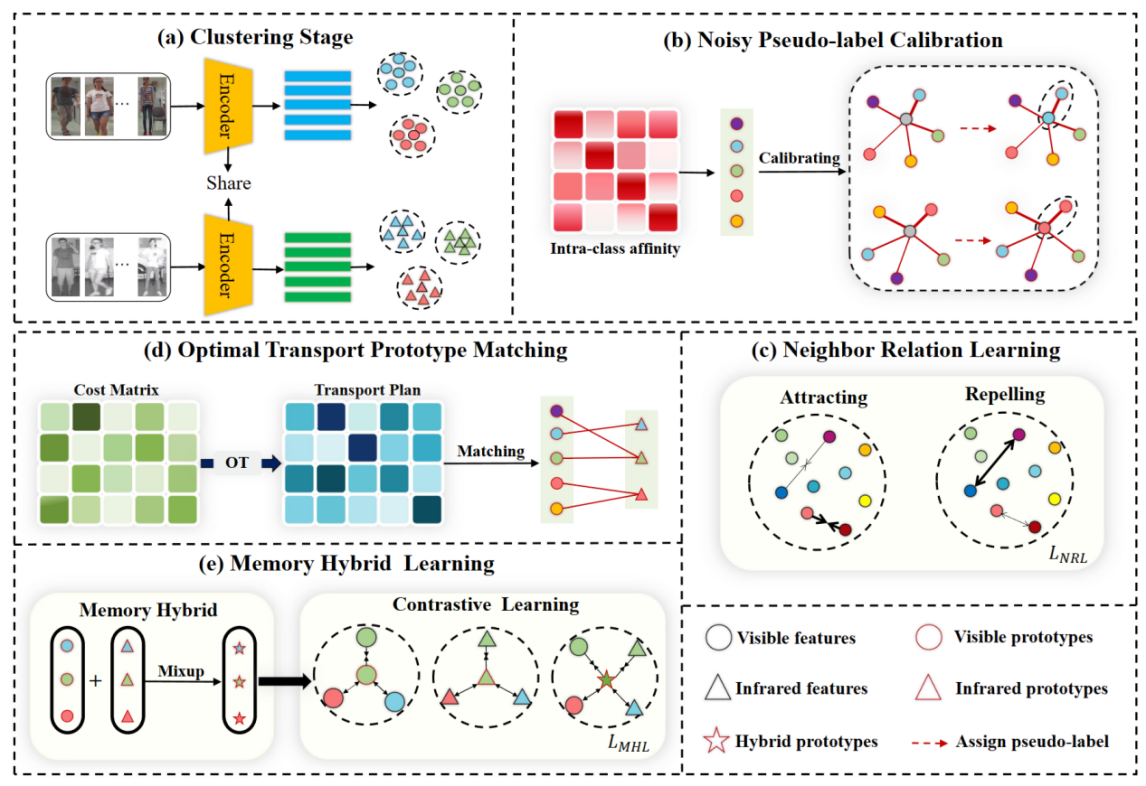
简介:本文的共同第一作者是信息学院2023级硕士生尹祥博和人工智能研究院2022级博士生施江鸣,通讯作者是其导师曲延云教授和谢源教授(华东师范大学),由张亚超(清华大学深圳研究院)、卢杨助理教授、张志忠(华东师范大学)等共同合作完成。无监督可见光-红外行人重识别(uSWI-&eDD)是一项极具挑战的任务,其目的是在没有任何标注的情况下匹配可见光和红外模态下的行人图像。最近,聚类伪标签方法已成为 USVI-ReID 的主要方法,但是不可靠的伪标签严重影响识别精度。为了解决这一问题,本文设计了一种基于邻居关系的鲁棒伪标签学习框架(RPNR)。具体而言,本文首先引入了一个简单而有效的噪声伪标签校准模块来校正噪声伪标签;设计了邻居关系学习模块,通过对所有样本间潜在的相互作用进行建模来降低较高的类内差异;进一步设计了最优传输原型匹配模块,以建立可靠的跨模态对应关系。在此基础上,通过内存混合学习模块,以联合学习特定模态信息和模态不变信息。在两个基准数据集(SYSU-MM01 和RegDB)上进行的综合实验表明,RPNR的性能优于当前最先进的GUR,Rank-1 性能提高了10.3%。
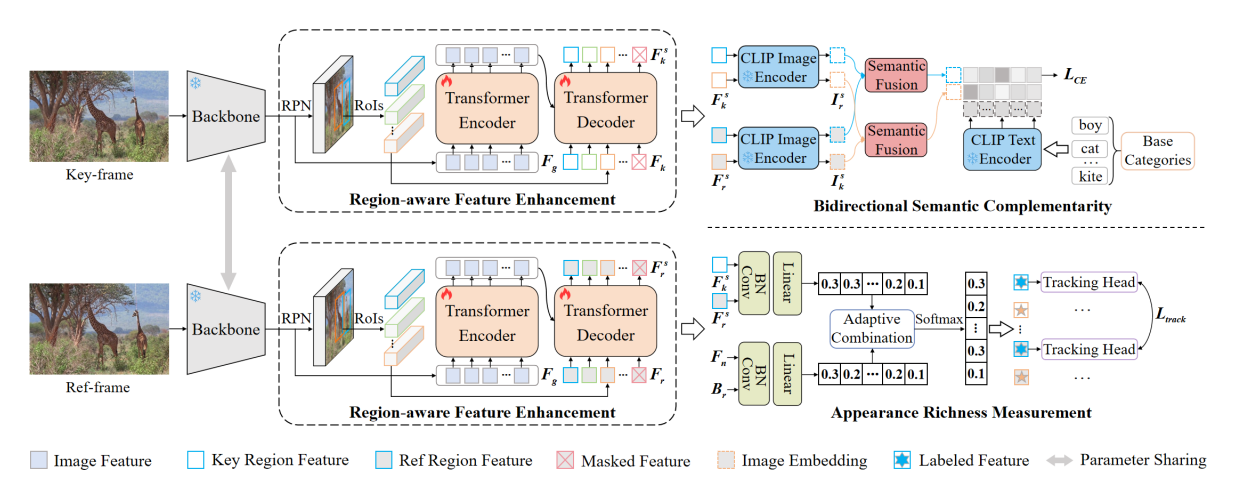
论文4:GLATrack: Global and Local Awareness for Open-Vocabulary Multiple Object Tracking
作者:黎光耀(厦门大学)、简亚军(厦门大学)、严严(厦门大学)、王菡子*(通讯作者,厦门大学)
简介:本文的第一作者是厦门大学人工智能研究院2023级博士生黎光耀,通讯作者是王菡子教授,由2022级硕士生简亚军、严严教授共同合作完成。针对开放词汇多目标跟踪在复杂环境中目标外观表征不明确、语义信息损失等关键问题,拟研究基于全局和局部感知的开放词汇多目标跟踪算法。该方法通过引入区域感知特征增强(RFE)模块细化全局知识来补充局部目标信息,增强语义表示并弥合图像特征图与区域特征之间的分布差距;提出双向语义互补(BSC)策略,在知识蒸馏过程中动态选择参考帧中的有价值信息,缓解关键帧中目标信息缺失导致的语义错位问题;引入外观丰富度测量(ARM)模块,为具有不同外观的目标提供适当的表示。提高模型的跟踪性能。
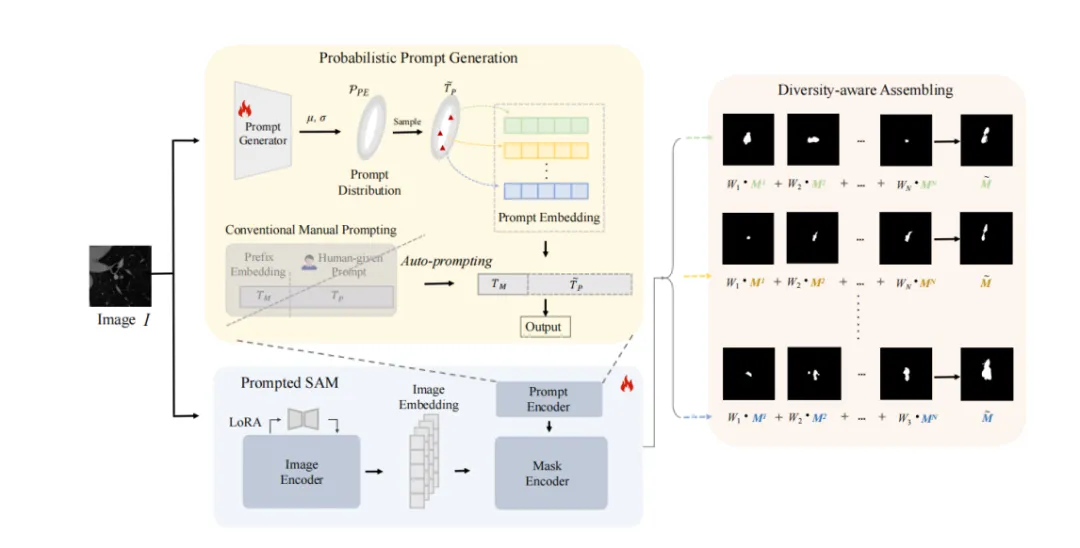
论文5:P2SAM: Probabilistically Prompted SAMs Are Efficient Segmentator for Ambiguous Medical Images
作者:黄誉之(共同一作,厦门大学)、李宸鑫*(共同一作,通讯作者,香港中文大学)、黄悦*(通讯作者,厦门大学)、丁兴号(厦门大学)、涂晓彤(厦门大学)
简介:本文的共同第一作者是信息学院2023级硕士生黄誉之和李宸鑫博士(香港中文大学),通讯作者是李宸鑫博士和黄悦教授,由丁兴号教授、涂晓彤助理教授等共同合作完成。单输入生成多个合理输出的能力对处理视觉场景中的固有歧义具有深远的影响,这在不同专家为单个医学图像提供不同语义分割注释的场景中尤为明显。现有的方法依赖于概率建模来描述这种模糊性,并依赖大量的多输出注释数据来学习这种概率空间。然而,当只有有限数量的模糊标记数据可用时,这些方法往往会失败,这在现实世界的应用中很常见。为了克服这些挑战,本文提出了一种新的框架,称为P2SAM,该框架在分割模糊对象时利用了分段任意模型(SAM)的先验知识。具体来说,本文深入研究了SAM在确定性分割中的固有缺点,即输出对提示的敏感性,并通过为提示引入先验概率空间,巧妙地将其转化为模糊分割任务的优势。实验结果表明,通过使用少量医生模糊注释的样本,本文的策略显著提高了医学分割的准确性和多样性。针对最先进方法的严格基准测试实验表明,本文的方法在较少的训练数据(仅使用5.5%的样本)下实现了卓越的分割精度和多样化的输出。P2SAM标志着在数据有限的现实世界场景中,概率模型的实际部署迈出了重要的一步。
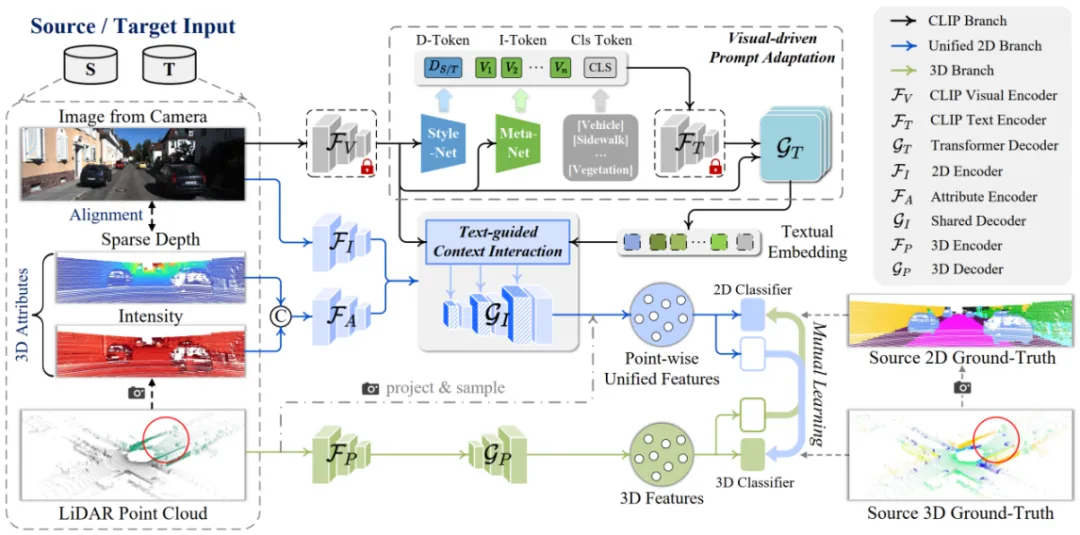
论文6:CLIP2UDA: Making Frozen CLIP Reward Unsupervised Domain Adaptation in 3D Semantic Segmentation
作者:吴垚(厦门大学)、邢明炜(厦门大学)、张亚超(清华大学深圳研究院)、谢源*(通讯作者,华东师范大学)、曲延云*(通讯作者,厦门大学)
简介:本文的第一作者是信息学院2021级博士生吴垚,通讯作者是其导师曲延云教授和谢源教授(华东师范大学),由2022级硕士生邢明炜、张亚超(清华大学深圳研究院)等共同合作完成。本文探索了如何利用多模态信息解决3D语义分割的域自适应问题。现有的方法通常试图通过对齐源数据和目标数据之间的特征来减轻域差异。然而,这种实现在应用于图像感知时存在不足,因为与点云相比,图像对环境变化的敏感性更高。为了解决这一问题,本文提出一种利用图像语言预训练模型(CLIP)的先验知识来提升跨域3D语义分割鲁棒性的框架 (CLIP2UDA)。首先,引入了一个视觉驱动的提示适应模块 (VisPA),通过预训练的视觉编码器生成的2D域特征,学习特定于任务的文本提示。其次,为了学习多模态域不变特征表示,提出了一个文本指导的上下文交互模块 (TexCI),通过跨解码器层进行类感知融合和语义感知融合,得到文本引导的视觉特征,然后将该特征与图像和属性特征融合,并在共享解码器中进行层次性交互,从而产生联合的视觉预测。最后,将3D特征与点级联合特征进行互学习,受益于视觉语言结构相关性,增强了多模态域不变特征的表示能力。该方法在Day/Night、USA/Singapore、vKITTI/sKITTI和A2D2/sKITTI自适应场景中显著优于目前最先进的跨模态UDA方法。
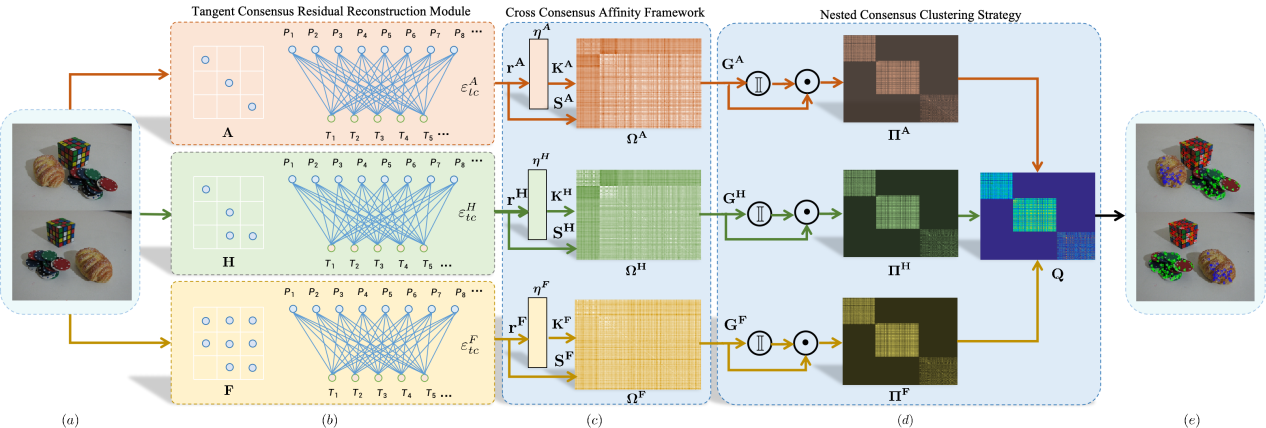
论文7:Multi-Model Fitting Driven by Diversity Consensus Pairing and Motion Estimation
作者:尹文玉(厦门大学)、林舒源(暨南大学)、卢杨*(通讯作者,厦门大学)、王菡子(厦门大学)
简介:本文的第一作者是厦门大学信息学院2023级博士生尹文玉,通讯作者是卢杨助理教授,由王菡子教授、林舒源博士(暨南大学)共同合作完成。多模型拟合存在大量噪声和异常数据,仅使用单一一致性或隐式融合模型来模拟数据点和模型假设之间的相关性往往会导致不正确的模型拟合。本文提出了一种基于多样一致性配对与运动估计的多模型拟合(CMMF)方法,该方法利用三种不同的一致性以及模型间的协作来提高多模型拟合的有效性。我们设计了一个切线一致性残差重建(TCRR)模块,用于在像素级捕获两点的运动结构信息。此外,我们引入了交叉一致性亲和度(CCA)框架,以加强数据点和模型假设之间的相关性。为了应对多体运动估计的挑战,我们提出了一种嵌套一致性聚类(NCC)策略,该策略将多模型拟合转化为运动估计问题。它明确地建立了模型之间的运动协作,并确保了多个模型良好拟合。
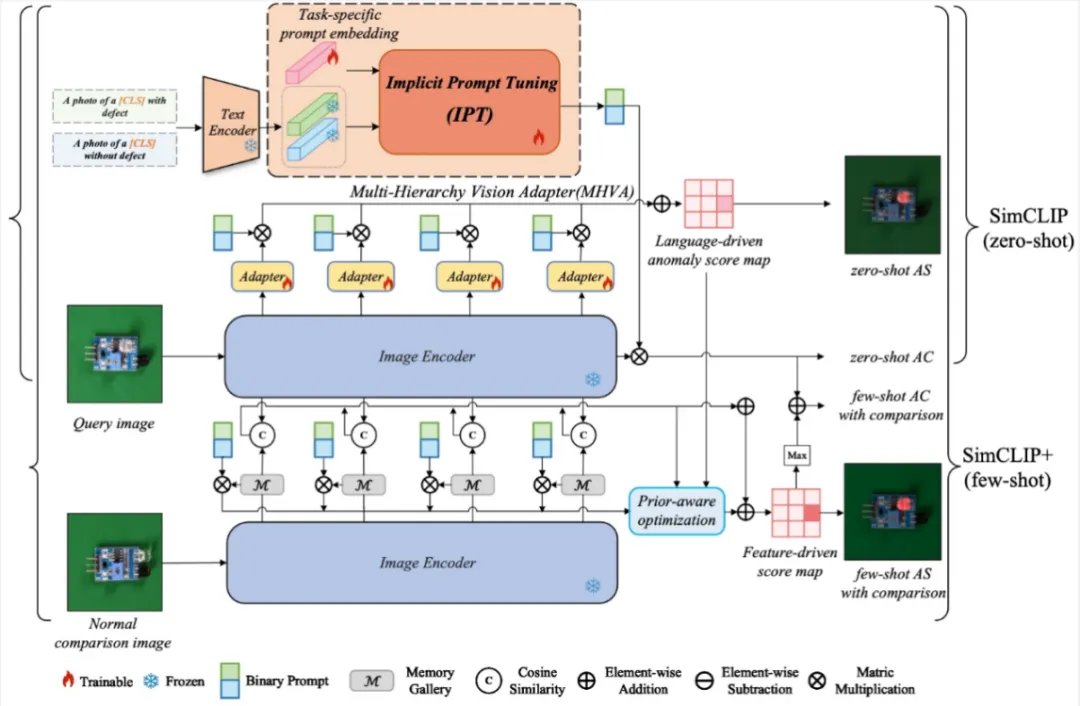
论文8:SimCLIP: Refining Image-Text Alignment with Simple Prompts for Zero-/Few-shot Anomaly Detection
作者:邓成浩(厦门大学)、徐浩特(厦门大学)、涂晓彤*(通讯作者,厦门大学)、丁兴号(厦门大学)、黄悦(厦门大学)
简介:本文的共同第一作者是人工智能研究院2022级硕士生邓成浩和徐浩特博士,通讯作者是涂晓彤助理教授,由丁兴号教授、黄悦教授等共同合作完成。最近,经过大规模Web数据完成预训练的视觉语言模型,在小零样本异常检测领域内展现出了优越的性能表现。然而,现有方法仍然存在两个问题。第一,文本提示需要通过大量的专家知识来构建。第二,当前的方法使用不对齐的高层语言特征和低层视觉特征来完成异常分割任务。基于此,本文提出了一个名为SimCLIP的方法,旨在通过多层级的视觉适配器(MHVA)和隐式提示学习模块(IPT)之间的双向适应来修正视觉语言特征不对齐的问题。SimCLIP只需简单的二分类文本提示就能高效完成零样本异常检测任务。此外,本文还提出了它的扩展版本SimCLIP+,通过整合视觉嵌入信息和跨模态协同信息来解决小样本场景下的异常检测任务。本文为预训练视觉语言模型高效适配具体的下游小零样本异常检测任务提供了新的视角。
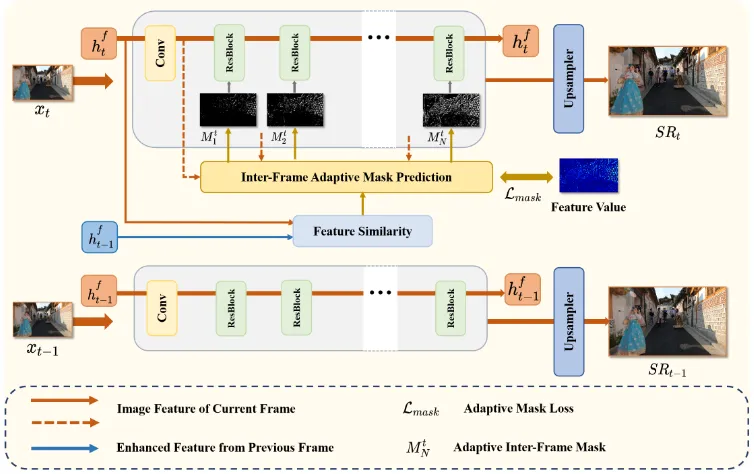
论文9:SkipVSR: Adaptive Patch Routing for Video Super-Resolution with Inter-Frame Mask
作者:艾泽坤(共同一作,厦门大学)、罗小同(共同一作,厦门大学)、谢源*(通讯作者,华东师范大学)、曲延云*(通讯作者,厦门大学)
简介:本文的共同第一作者是信息学院2021级硕士生艾泽坤与2020级博士生罗小同,通讯作者是其导师曲延云教授和谢源教授(华东师范大学)。本文提出了基于自适应跳步的视频超分辨率动态推理方法,以动态网络结构的角度实现模型推理加速。同一视频序列往往针对同一场景,帧间特征具有高度相似性,但所有帧间特征均采用相同深度的模块进行特征融合,这造成了模型结构的冗余。针对这一问题,本文将动态推理技术拓展至视频超分辨率任务,以动态网络结构的角度探索模型加速问题。通过探索序列帧之间的特征相似性,设计自适应掩码生成器来指示模块的执行。为保证模型精度,该方法设计了高维空间特征约束,以减少前序帧所带来的累积误差。在公开数据集上的实验结果表明,该方法能在减少计算资源消耗的同时,仍能保持图像重构纹理。