近日,我中心9篇论文被第39届人工智能与机器学习领域顶级会议Neural Information Processing Systems(简称NeurIPS,CCF A类会议)录用。本届 NeurIPS共收到 21575 份有效论文投稿,录用5290 篇,录用率为 24.52%,录用论文简要介绍如下:(按第一作者姓氏拼音排序)
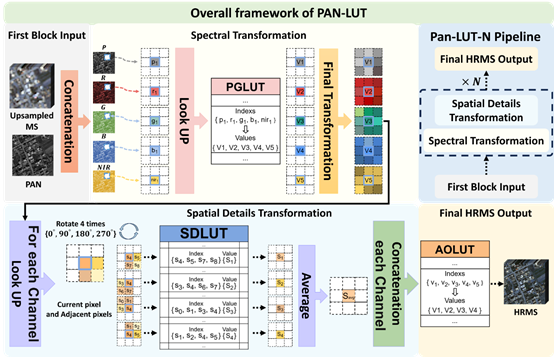
论文1:Pan-LUT: Efficient Pan-sharpening via Learnable Look-Up Tables
简介:通过用可学习的查找表替换复杂的深度神经网络操作,实现资源有限环境下的超大分辨率遥感图像融合。本文提出了一种可学习的查找表架构Pan-LUT。将PAN图像像素信息作为监督的通道差异索引技术以及局部像素差异的索引技术,分别构建用于补获光谱信息和局部纹理信息的查找表。此外,通过在训练时引入旋转增强策略,进一步增大感受野,实现更加精细的纹理细节。查找表的简单的索引和线性插值技术对比于复杂的卷积运算或注意力计算有着明显的计算效率优势。实验结果表明,Pan-LUT可以在1ms内处理8K大小的遥感图像,同时有着对比于神经网络方法的性能,有着极高的实际应用的价值。
该论文第一作者是厦门大学信息学院信息与通信工程系2023级硕士生蔡中南,通讯作者是丁兴号教授。
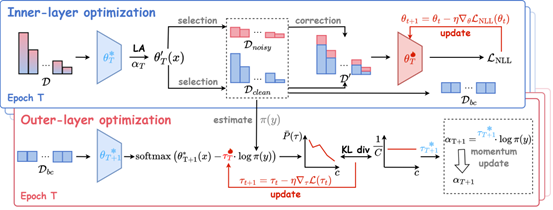
论文2:Unlocker: Disentangle the Deadlock of Learning from Label-noisy and Long-tailed Data
简介:长尾噪声标签学习致力于处理真实世界数据中长尾分布与标签噪声共存场景下的模型学习难题。我们发现,该场景下存在“死锁”困境:标签噪声学习方法需依赖无偏预测实现标签识别和修正,进而恢复真实类分布,而长尾学习方法(如logit调整)则需以真实类分布为先验,实现对模型有偏预测的矫正,二者形成循环依赖。为解耦这一死锁,本文提出双层优化框架 Unlocker:内层优化融合噪声标签方法与长尾学习方法,实现公平的噪声标签识别与修正;外层优化则通过自适应优化调整强度,动态平衡模型偏见。实验结果表明,Unlocker 在多个基准数据集上的性能均显著优于当前主流的长尾噪声标签学习方法。
该论文第一作者是厦门大学2023级硕士生陈姝,通讯作者是卢杨助理教授,由2023级本科生徐紘濬、2024级硕士生张瑞弛、李梦柯助理教授(深圳大学)、张永岗助理教授(香港科技大学)、韩波副教授(香港浸会大学)、张晓明教授(香港浸会大学)、王菡子教授合作完成。
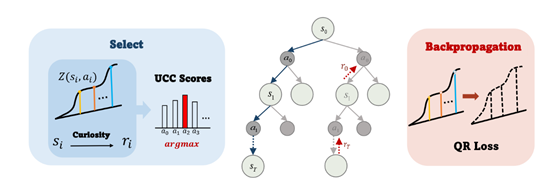
论文3:PlanU: Large Language Model Decision Making through Planning under Uncertainty
简介:针对大语言模型在不确定性环境下难以实现稳健规划这一关键难题,论文了提出PlanU方法—— 一种基于大语言模型的规划框架,其核心是在蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)中融入对不确定性的建模。其技术核心包括两个部分。值分布建模:PlanU 创新地将蒙特卡洛树搜索中各节点的“收益”(return)建模为 “分位数分布”,通过一组分位数精准表征收益的分布特征,以此更充分地捕捉决策过程中存在的不确定性。好奇心驱动的评估机制:为优化树搜索策略,PlanU 提出“带好奇心的上置信界”(Upper Confidence Bounds with Curiosity, UCC)评估机制,通过量化评估蒙特卡洛树各节点的好奇心分数,有效缓解 LLM 的不确定性问题,弥补了传统搜索策略在适配 LLM 决策场景时的不足。
文章在 WebShop、TravelPlanner 等权威基准测试中验证,PlanU 在大语言模型不确定性决策任务上表现显著优于各类基线方法,且兼具环境适应性、资源效率与跨模型稳健性。
该论文共同第一作者是厦门大学信息学院2023级硕士生邓子微、2023级硕士生邓冕,通讯作者是沈思淇长聘副教授。由梁辰景、高泽铭、硕士毕业生马陈楠、林晨兴、张海鹏、梅松竹副研究员(国防科技大学)、王程教授共同完成。
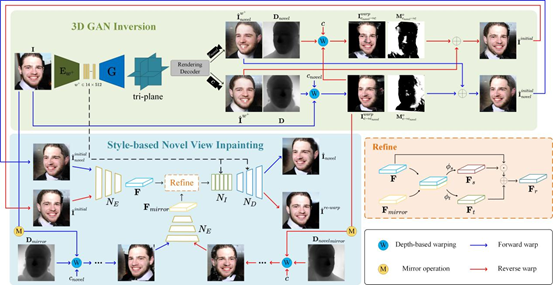
论文4:WarpGAN: Warping-Guided 3D GAN Inversion with Style-Based Novel View Inpainting
简介:本文针对单张图像的3D GAN反演问题,提出了一种新的方法WarpGAN,用于实现基于单张图像的新视角合成。现有方法多关注可见区域的重建,而对遮挡区域的生成仅依赖于3D GAN的生成先验,导致因低比特率潜在码造成的信息丢失使得遮挡区域生成质量差。为此,本文引入了变形与修复策略,将图像修复融入3D GAN反演。首先利用反演编码器将单视图图像投影到作为3D GAN输入的潜在编码;接着利用3D GAN生成的深度图进行新视角的变形;最后提出的SVINet借助对称先验和针对相同潜在编码的多视图图像对应关系,对变形图像中的遮挡区域进行修复。定量和定性实验表明,该方法均优于现有的先进方法。
该论文第一作者为厦门大学信息学院2024级硕士生黄锴涛,通讯作者是严严教授,由Jing-Hao Xue(UCL)、王菡子教授共同合作完成。
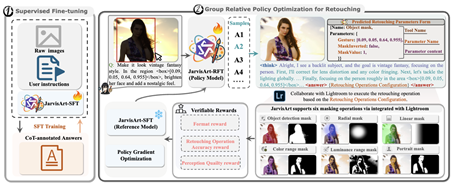
论文5:JarvisArt: Liberating Human Artistic Creativity via an Intelligent Photo Retouching Agent
简介:照片修饰已成为现代视觉叙事的重要组成部分,使用户能够捕捉美感并展现创意。如Adobe Lightroom 等专业工具虽然功能强大,但操作门槛较高;现有 AI 方案虽实现自动化,却缺乏足够的可调节性与泛化能力,难以满足多样化的个性化需求。为填补这一空白,本文提出 JarvisArt,一个由多模态大语言模型(MLLM)驱动的智能体。它能理解用户意图,模拟专业修图师的思维流程,并在Lightroom中智能调用200多种修饰工具。其训练包括两个阶段:①通过链式思维监督微调掌握基础推理与工具使用;②采用面向修饰的组相对策略优化(GRPO-R)提升决策与执行能力。同时,本文提出“Agent-Lightroom协议”,以实现与 Lightroom 的无缝集成。为评估性能,本文构建了真实用户编辑驱动的新基准 MMArt-Bench。实验表明,JarvisArt 在交互性、泛化能力与局部/全局控制方面表现优异。在内容保真度指标上,其在MMArt-Bench 中比GPT-4o提升60%,且保持出色的指令遵循能力,展现出智能修图的新潜力。
该论文的共同第一作者是厦门大学信息学院信息与通信工程系2023级硕士研究生林云龙、林子旭和2024级硕士研究生林坤杰。通讯作者为丁兴号教授,由颜水成教授(新加坡国立大学)等共同合作完成。
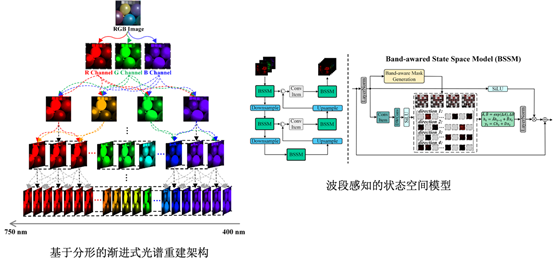
论文6:FRN: Fractal-Based Recursive Spectral Reconstruction Network
简介:通过光谱重建从 RGB 图像生成高光谱图像(HSI),能够显著降低 HSI 的获取成本。本文提出了一种基于分形的递归光谱重建网络(Fractal-Based Recursive Spectral Reconstruction Network, FRN)。与现有尝试直接在一次性操作中整合 R、G、B 三个通道的全光谱信息的范式不同,FRN 将光谱重建视为一个逐步推进的过程:既可以从宽带到窄带逐层预测,也可以采用由粗到精的方式来预测下一个波长。受数学中分形思想的启发,FRN 通过递归调用原子重建模块,建立了一种全新的光谱重建范式。在每次调用中,模型仅利用相邻波段的光谱信息,为下一个波长图像的生成提供线索,这符合光谱数据的低秩特性。此外,本文设计了一种波段感知的状态空间模型,在生成过程的不同阶段采用像素差异化的扫描策略,从而进一步抑制由反射率差异引起的低相关区域干扰。大量跨数据集的实验结果表明,FRN 在定量和定性评估中均优于当前最先进的方法,展现出更优越的重建性能。
该论文第一作者是厦门大学信息学院信息与通信工程系2021级博士生孟戈,通讯作者是丁兴号教授。
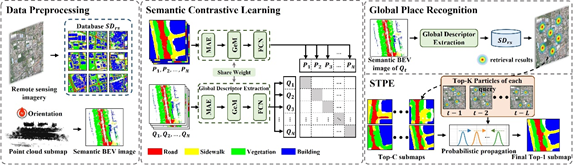
论文7:L2RSI: Cross-view LiDAR-based Place Recognition for Large-scale Urban Scenes via Remote Sensing Imagery
简介:激光雷达位置识别旨在在GPS信号较弱甚至拒止时,从全球坐标系下预构建的数据库中检索最接近的匹配及其位置。现有激光雷达位置识别依赖于事先采集的新鲜的三维地图,其获取和维护是耗时和昂贵的。为此,本文首次提出了一个使用高分辨率遥感影像在大规模(超过100平方公里)城市场景中进行跨视角、跨模态激光雷达位置识别的框架——L2RSI。L2RSI通过语义对比学习网络将激光雷达点云鸟瞰图和遥感子图统一到一个共享的语义空间中,克服了跨域跨视角数据的巨大差异。此外,L2RSI通过空间-时间粒子估计算法,利用多个高斯模型的混合来聚合时空信息,推断当前位置的概率密度,从而进一步提高全局位置识别的性能。
该论文第一作者是厦门大学信息学院2023级博士生石子威,通讯作者是臧彧副教授。由张潇然、续文静、夏彦副教授(中国科学技术大学)、沈思淇长聘副教授、王程教授共同完成。
论文8:DynamicVerse: Physically-Aware Multimodal Modeling for Dynamic 4D Worlds
简介:理解动态物理世界——其不断演化的三维结构、真实的运动过程,以及带有文本描述的语义内容——对于实现人机交互至关重要,这也使具身智能体能够具备类似人类的能力,在真实环境中进行感知与行动。然而,现有数据集往往依赖于有限的模拟器,或是利用传统的结构-从-运动(Structure-from-Motion)方法进行尺度注释,并且在描述性字幕方面存在局限,这极大限制了基础模型从互联网单目视频中准确理解真实世界动态的能力。为弥补这一缺陷,本文提出 DynamicVerse ——一个面向真实视频的物理尺度、多模态 4D 建模框架。我们利用大规模视觉、几何与多模态模型来解析度量尺度下的静态几何、真实的动态运动、实例级掩码以及整体性的描述性字幕。通过结合窗口化的束调整(Bundle Adjustment)与全局优化,我们的方法能够将长时间的真实视频序列转化为完整的 4D 多模态格式。DynamicVerse 构建了一个大规模数据集,包含 10 万+ 视频、80 万+ 标注掩码和 1000 万+ 帧,均来自互联网视频。我们在三个基准任务上进行了实验评估——视频深度估计、相机位姿估计以及相机内参估计。结果表明,该 4D 建模方法在物理尺度测量与全局精度方面均显著优于现有方法。
该论文共同第一作者为信息学院信息与通信工程系2021级硕士生温凯润和黄誉之,通讯作者为丁兴号教授。

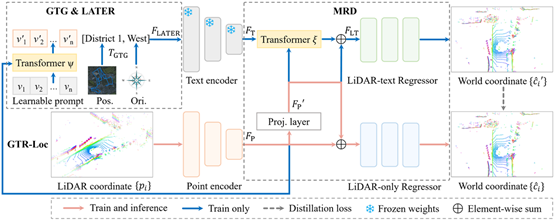
论文9:GTR-Loc: Geospatial Text Regularization Assisted Outdoor LiDAR Localization
简介:本文提出了一种名为 GTR-Loc 的新型激光雷达定位框架,旨在解决因不同场景几何特征相似而导致的定位歧义性难题。该方法创新地引入地理空间文本(位置和方向描述)作为一种正则化手段,以独特的文本线索消除歧义,从而提升定位精度。此外,本文还提出了一种模态削减蒸馏策略,将文本知识迁移到定位模型中,使得模型在推理阶段无需文本输入,仅依靠激光雷达也可实现高性能定位。实验证明,该方法在多个户外大规模数据集上的表现显著优于当前最先进的定位方法。
该论文第一作者是厦门大学信息学院2022届博士毕业生于尚书,通讯作者是王程教授。并由2025届博士毕业生李文、2024届博士毕业生袁直敏、2020级博士生孙啸天、王欣讲师(东北大学)、王思洁博士后(南洋理工大学)、厍睿教授(北京航空航天大学)共同完成。