近日,我中心16篇论文被人工智能领域顶级会议IEEE/CVF Conference on Computer Vision and Pattern Recognition(简称CVPR,CCF A类会议)录用。本届CVPR共有16,092篇论文进入评审流程,录用4090 篇,录用率为25.42%,录用论文简要介绍如下:(按第一作者姓氏拼音排序)
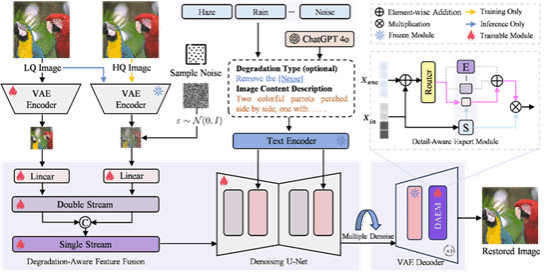
论文1:UniLDiff: Unlocking the Power of Diffusion Priors for All-in-One Image Restoration
简介:预训练潜在扩散模型(如Stable Diffusion)展现出的卓越建模能力,有望为全能图像修复(All-in-One Image Restoration, AiOIR)任务提供强大的生成先验支持。为了在统一架构下精准适配多种退化并弥补恢复过程中的细节丢失,本文提出了 UniLDiff 框架。该框架通过引入退化感知特征融合机制(DAFF)与细节感知专家模块(DAEM),深度解锁扩散先验的修复潜力:DAFF通过解耦融合和自适应调制将低质量特征动态注入去噪迭代过程,实现对多种退化的隐式建模与空间自适应引导;DAEM通过专家路由机制动态激活特定分支,利用多尺度特征补偿潜在空间压缩引起的信息损耗,显著提升纹理与细节的重建精度。实验结果表明,UniLDiff在多项修复任务及零样本未知退化场景下均取得了先进的性能,验证了扩散先验在通用图像修复领域中的巨大应用潜力。
该论文第一作者是厦门大学信息学院2024级硕士生程梓涵,共同通讯作者是曲延云教授和谢源教授(华东师范大学),由周亮太、陈典、唐妮、罗小同(香港理工大学)共同合作完成。
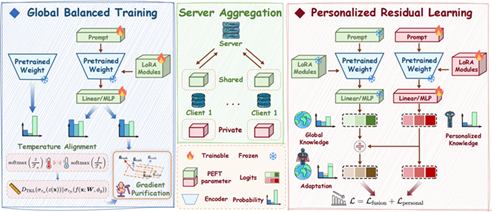
论文2:Fine-Tuning Impairs the Balancedness of Foundation Models in Long-tailed Personalized Federated Learning
简介:在个性化联邦学习中,利用基础模型是应对客户端数据异构性的重要途径。然而,真实场景下往往同时面临非独立同分布与长尾分布的双重挑战。在异构长尾数据上直接微调会严重侵蚀基础模型原生的零样本知识平衡性;同时,现有的融合式个性化方法不仅无法解决该问题,还会将这种全局偏差放大并传递给客户端,进一步损害识别性能。为此,本文提出一种新的个性化联邦学习方法FedPuReL。该方法首先对下游任务的更新梯度进行提纯,剔除对模型原生平衡性具有负面影响的梯度,使全局模型保持良好的平衡性;进一步地,构建残差式个性化模型,使客户端在平衡的全局模型基础上进一步学习个性化知识,从而在适配本地数据的同时兼顾知识平衡性。实验结果表明,该方法在多个联邦长尾基准数据集上能够同时提升全局模型与个性化模型的性能表现,显著优于现有SOTA方法。
该论文第一作者是厦门大学信息学院2024级硕士生侯世豪,通讯作者是卢杨长聘副教授,由2025级硕士生尚驰凯、2025级硕士生杨知衡、2025级博士生杨嘉诚、尚心怡(UCL)、高俊龙助理教授、张逸群(广东工业大学)共同合作完成。
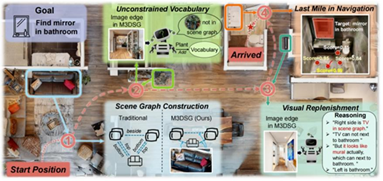
论文3:MSGNav: Unleashing the Power of Multi-modal 3D Scene Graph for Zero-Shot Embodied Navigation
简介:现有零样本导航方法在构建显式三维场景图的过程中将丰富的视觉信息压缩为纯文本的目标关系。这一过程导致了构建成本高昂、视觉证据不可逆丢失以及场景图词汇表受限等问题。为解决这些问题,本文首先提出了多模态三维场景图(M3DSG),通过动态分配图像替代文本关系边来保留丰富的视觉线索。基于多模态三维场景图,进一步开发了零样本导航系统MSGNav来执行更高效准确的导航。此外,本文进一步识别出零样本导航中的“最后一公里”难题——如何确定具有最优目标视野的可行导航点,并提出基于可见性的视角决策模块来明确解决该问题。实验结果表明,MSGNav在具有挑战性的GOAT-Bench和HM3D-ObjNav基准测试中均取得业界领先水平。
该论文第一作者是信息学院2024级博士生黄勋,共同通讯作者是温程璐教授、李伟欣副教授(北京航空航天大学)。由赵世佳,张万发,王蕴红教授(北京航空航天大学)等共同合作完成。
论文4:Direct Segmentation without Logits Optimization for Training-Free Open-Vocabulary Semantic Segmentation
简介:开放词汇语义分割旨在利用开放词汇提示分割图像中的任意类别区域,这就要求现有方法具备像素级的视觉-语言对齐能力。通常,这种能力涉及计算视觉特征和语言特征之间的余弦相似度(即logits),并最小化logits与真实值(GT)之间的分布差异,从而生成最优logits,进而用于构建分割图。然而,这种方法依赖于耗时的迭代训练或模型特定的注意力机制。本文提出了一种更直接的方法,通过直接推导分割图的解析解来避免logits优化过程。我们提出了一个关键假设:分布差异编码了语义信息;具体而言,这种差异在同一类别的图像块之间表现出一致性,但在不同类别的图像块之间表现出不一致性。基于此假设,我们直接利用这种分布差异的解析解作为语义图。换句话说,我们将分布差异的优化重新表述为推导其解析解,从而消除了耗时的迭代训练,使我们摆脱了模型特定的注意力调节,并在八个基准数据集上实现了最先进的性能。
论文第一作者是厦门大学信息学院2023级博士生李佳豪,共同通讯作者曲延云教授和张亚超助理教授(厦门大学)。

论文5:Towards Motion Turing Test: Evaluating Human-Likeness in Humanoid Robots
简介:近年来,人形机器人在运动生成与控制方面取得了显著进展,动作看起来越来越自然,但“是否真的像人类”仍缺乏统一评估标准。本文受图灵测试启发,提出了Robot Motion Turing Test(机器人行为图灵测试),通过仅保留运动学信息,让人类判断动作来源,从运动学角度评估机器人运动的类人程度。同时,本文构建了首个包含人类与人形机器人同类动作数据且包含人类评分标注的HHMotion 数据集,并进一步提出自动预测动作类人度的基准任务与模型。研究发现,即使在视觉外观因素被消除的情况下,当前机器人动作仍与人类存在明显差距,尤其在跳跃、拳击等高动态场景中更为突出。该工作为机器人行为图灵测试提供了以运动为中心的评估新范式,也为未来更自然的机器人运动生成奠定了基础。
该论文共同第一作者是厦门大学信息学院2025级博士生李明哲和2024级硕士生刘梦茵,通讯作者是沈思淇长聘副教授,由吴泽凯、林心成、张俊圣、颜明、谢曾烨、张长旺(OPPO研究院)、温程璐教授、许岚助理教授(上海科技大学)、王程教授共同合作完成。

论文6:V2U4Real: A Real-world Large-scale Dataset for Vehicle-to-UAV Cooperative Perception
简介:自动驾驶感知系统通常受限于遮挡、盲区以及有限的感知范围。已有的车车协同和车路协同范式感知主体为地面视角,难以有效应对大规模遮挡与远距离感知需求。本文提出首个面向车与无人机协同目标感知的大规模多模态真实场景数据集V2U4Real。V2U4Real由搭载有激光雷达与RGB相机的地面车辆与无人机协同采集,采集场景覆盖城市街道、校园以及乡村道路等多种交通环境,共包含超过56K帧激光雷达数据、56K张多视角相机图像,涵盖四类目标的70万个三维标注框。此外,本文构建了单智能体三维目标检测、协同三维目标检测以及多目标跟踪等基准任务。对多种当前先进模型的评估结果表明,车与无人机协同感知可显著提升复杂场景感知鲁棒性与远距离感知能力。
该论文共同第一作者是厦门大学信息学院2025级硕士生李伟佳和2023级硕士生项浩恩,通讯作者是温程璐教授。由王天旭、吴帅兵、夏启明、王程教授共同合作完成。

论文7:JarvisEvo: Towards a Self-Evolving Photo Editing Agent with Synergistic Editor-Evaluator Optimization
简介:在迈向通用人工智能的道路上,我们一直在思考一个问题:现有的 Image Editing Agent,真的“懂”修图吗?大多数基于 LLM/VLM 的智能体,本质上更像是一个“盲目的指挥官”。它们能流利地写出修图代码或调用 API,但在按下回车键之前,它们看不见画布上的变化,也无法像人类设计师那样,盯着屏幕皱眉说:“这张对比度拉太高了,得往回收到一点。”这种感知与决策的割裂,直接导致了“指令幻觉”,或者说模型在进行盲目的“脑补”。由于缺乏视觉反馈,模型往往凭空想象下一步操作,导致结果与用户的初衷南辕北辙。此外,在传统强化学习中经常依赖于静态的奖励模型。随着模型的不断训练,它很容易学会如何“讨好”这个固定的打分器,导致 Reward Hacking——即分数很高,但审美并没有真正提升。 为了打破这一僵局,JarvisEvo应运而生。它不仅仅是一个连接 Adobe Lightroom 的自动化工具使用者,更是一次大胆的探索:探索 Agent 如何通过“内省”,真正实现自我进化。
该论文共同第一作者为厦门大学信息学院 2023 级硕士生林云龙、林子旭、2024 级硕士生林坤杰和腾讯混元研究员王林青,通讯作者为丁兴号教授,由腾讯混元研究员王林青、王春雨、卢清林共同合作完成。

论文8:SECOS: Semantic Capture for Rigorous Classification in Open-World Semi-Supervised Learning
简介:在开放世界半监督学习中,模型从包含已知类别和未知类别的有标签数据和无标签数据中学习。在实际的开放世界半监督学习应用中,模型需要通过直接选择候选标签集中与输入样本语义上最相关的标签来执行严格的分类。现有的开放世界半监督学习方法未能实现这一点,因为未知类样本是在没有明确监督信号的环境下训练的,这些方法缺乏提取潜在语义信息的机制,导致其预测的标签与候选文本标签没有语义上的对应关系。为了解决这一问题,本文提出了开放世界半监督学习的语义捕获框架SECOS,它无需后处理即可直接从候选标签集中预测文本标签,从而满足实际开放世界半监督学习应用的需求。SECOS利用外部知识捕获已知类别和未知类别潜在的语义信息,并让模型建立起样本视觉特征和潜在文本特征的匹配关系,为未知类别样本的训练提供显式监督信号。大量实验表明,即使在更宽松的后处理设置下评估现有的开放世界半监督学习方法,而SECOS在没有后处理辅助的情况下仍然比他们的整体性能高出5.4%。
该论文第一作者是厦门大学信息学院2023级硕士生刘赫昭,通讯作者是卢杨长聘副教授,由2025级博士生杨嘉诚、高俊龙助理教授以及李梦柯(深圳大学)、张逸群(广东工业大学)、Shreyank N Gowda(英国诺丁汉大学)共同合作完成。
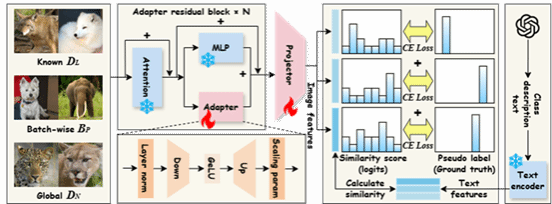
论文9:Protect to Adapt: Subspace-Constrained Adaptation with Ranked Negative Prompt Feedback for Few-Shot Action Recognition
简介:将视觉语言模型适配到小样本动作识别任务时,往往需要在准确率与稳定性之间做权衡:面向特定任务的性能提升可能会触发对领域通用知识的灾难性遗忘,并降低类别间的区分度。在小样本任务的 episode 中,每个查询样本通常只与一个正类以及少量负类进行对比,使得文本编码器接触到的提示多样性有限,也较少在决策边界附近看到困难反例。因此,本文提出一种P2A (Protect-to-Adapt) 微调方法,通过估计预训练骨干网络的主语义子空间,并将低秩更新约束在其正交补空间内,从而在允许任务特定适配的同时保留领域通用语义。同时,利用大语言模型生成经过验证器筛选、难度逐步递增的负提示。这些类别相关的困难反例能够在小样本条件下扩大类间间隔、锐化决策边界。在仅训练骨干网络 2% 参数的情况下,P2A 在五个FSAR 基准上达到最先进性能,并在跨数据集的持续学习设置中显著缓解灾难性遗忘:模型无需回放,即可依次适配多个视频数据集。
该论文第一作者是厦门大学人工智能研究院2024级博士生齐汉涛,通讯作者是王菡子教授,由严严教授与高俊龙助理教授共同合作完成。
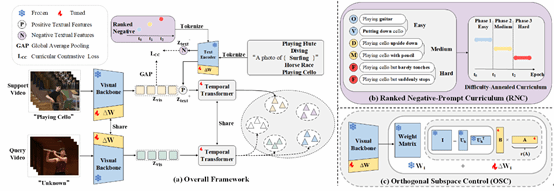
论文10:UZ3DVG: Unaided Zero-Shot 3D Visual Grounding with Generated Language Conditions
简介:零样本三维视觉定位(Zero-Shot 3DVG)旨在不依赖人工实例级描述标注的条件下,根据自然语言描述在三维场景中定位目标物体。针对现有方法在推理阶段依赖额外2D图像输入,或需要与LLM/VLM进行多轮交互而导致推理延迟高、计算开销大、部署复杂度高的问题,本研究提出了基于生成语言条件的无辅助零样本三维视觉定位方法(UZ3DVG):在推理阶段仅使用三维点云和文本描述,不依赖外部模型。在训练阶段,本团队设计了开放词汇多源空间标注与推理链生成器,从开放场景中的RGB-D图像或3D投影的2D图像生成空间伪标签与推理链,以训练一个具备稳健空间推理能力的轻量级3DVG模型。对此,本研究通过推理链蒸馏模块(RCD),将较大的教师网络提取的推理知识迁移到轻量级学生网络,并引入几何感知空间建模(GeoSM)模块联合建模全局与局部几何关系,辅助文本推理与3D空间结构对齐,进一步提升模型空间推理及定位能力。实验结果表明,UZ3DVG在ScanRefer和NR3D上取得零样本SOTA性能,推理速度达7.69 FPS,约为现有SOTA方法的38倍,建立了开放场景下零样本3DVG的新范式。
该论文第一作者为厦门大学信息学院2024级博士生谭文斌,共同通讯作者为张亚超助理教授和曲延云教授,由2024级硕士生林嘉文与谢源教授(华东师范大学)共同完成。
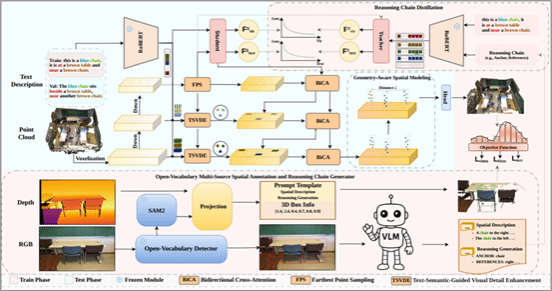
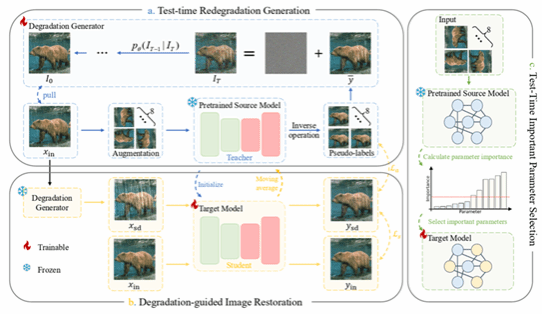
论文11:Degradation-Consistent Test-Time Adaptation for All-in-One Image Restoration
简介:一体化图像恢复(AiOIR)方法在处理多种退化方面已取得了显著进展。然而,当测试分布偏离训练分布时,其性能往往会明显下降。因此,探索面向 AiOIR 的测试时自适应方法具有重要意义。为了在不访问源数据、也不进行重新训练的情况下,使预训练的 AiOIR 模型适应未见过的退化分布,需要解决两个关键挑战:一是设计可靠的伪监督信号,二是稳定自适应过程。基于这样一个观察:同一场景的多个退化版本应当映射到一致的干净图像,本文提出了退化一致性的测试时自适应方法(Degradation-Consistent Test-Time Adaptation, DCTTA)。DCTTA 包含三个核心组成部分:(1)测试时再退化生成,通过基于扩散模型的生成器构建伪退化–干净图像对,以实现分布对齐;(2)退化引导的图像恢复,通过自监督一致性损失实现域自适应;(3)测试时重要参数选择,有选择地更新对退化敏感的参数,从而在保持预训练知识的同时确保自适应过程的稳定性。在多个任务和具有挑战性的分布偏移场景下的大量实验表明,DCTTA 相比当前最先进的 AiOIR 基线方法具有稳定优势,在 Rain100H 数据集上最高可实现 +4.57 dB 的 PSNR 提升。
该论文共同第一作者为厦门大学信息学院2024级博士唐妮和2023级硕士聂声豪,通讯作者为曲延云教授和谢源(华东师范大学),由罗小同(香港理工大学)共同合作完成。
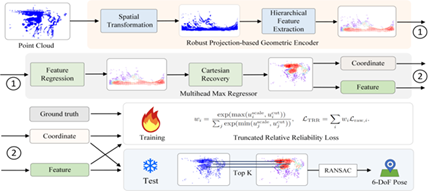
论文12:LEADER: Learning Reliable Local-to-Global Correspondences for LiDAR Relocalization
简介:激光雷达重定位能够在复杂三维环境中提供精确的六自由度位姿估计。现有基于学习的回归方法通过直接预测全局位姿来提供高效解决方案,无需显式存储地图。然而,这类方法在复杂场景中往往表现欠佳,主要原因是它们对所有预测点采用同等权重处理,导致容易受噪声和外点影响。本文提出一种基于几何编码器增强的鲁棒激光雷达定位方法LEADER。具体来说,提出一种基于投影的鲁棒几何编码器架构,通过捕获多尺度几何特征来增强几何表示的描述能力;此外设计了TRR损失函数,建模点的可靠性并抑制不可靠预测的影响。在Oxford RobotCar和NCLT数据集上的实验表明,LEADER方法优于SOTA方法,分别降低了24.1%和73.9%的定位误差。
该论文第一作者是信息学院2023级硕士生吴建实,通讯作者是敖晟助理教授,由朱明航、刘敦强、毕业生李文(布里斯托大学)、沈思淇副教授、温程璐教授、王程教授共同合作完成。
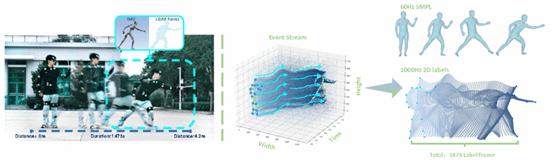
论文13:FlashCap: Millisecond-Accurate Human Motion Capture via Flashing LEDs and Event-Based Vision
简介:毫秒级运动计时对快速运动分析至关重要,在体育竞技等场景中毫秒之差往往决定成败。受限于高帧率标注数据的匮乏,毫秒级运动计时在姿态估计领域长期被忽视,而现有专业高速相机方案成本高昂且难以普及、对光照敏感且计算复杂度高,难以在日常场景中普及。为此,本文提出首个基于闪烁LED的毫秒级运动捕捉系统FlashCap。首先,利用该系统构建了包含事件相机、RGB等多模态的人体运动数据集FlashMotion;其次,针对毫秒级运动计时和超快人体动作捕捉任务,设计了基线网络ResPose,通过融合事件流与RGB特征预测残差姿态。实验表明,ResPose将姿态误差显著降低了约40%并实现了毫秒级计时精度,为高频微动态分析开辟了新途径。
该论文第一作者是厦门大学信息学院2024级硕士生吴泽凯、2023级硕士生范书琪,通讯作者是沈思淇长聘副教授,由刘梦茵、罗裕华、林心成、颜明、吴俊豪、毕业生林修弘、马月昕副教授(上海科技大学)、温程璐教授、许岚助理教授(上海科技大学)、王程教授共同合作完成。
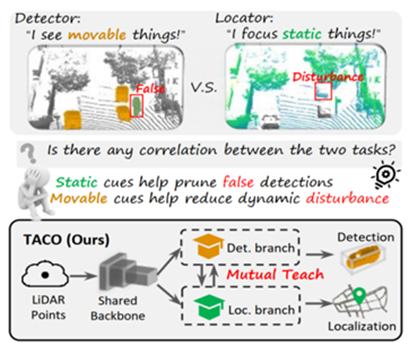
论文14:TACO: Task-Aware Contrastive Learning for Joint LiDAR Localization and 3D Object Detection
简介:自车定位和目标感知是自动驾驶车和智能机器人的关键任务。激光雷达视觉定位是对GNSS定位系统的有效补充手段。现有系统通常将定位与检测模型分离设计、分别优化,这导致计算冗余,也限制了跨任务知识迁移的潜力。此外,两项任务在语义关注与几何先验上存在差异,导致特征表示层面产生冲突,简单共享特征的多任务训练会导致性能下降。针对以上问题,本文提出了一种视觉定位和目标检测多任务学习框架TACO,通过对静态场景的几何结构特征与可移动目标的语义判别特征进行解耦,从而建立两个任务在同一框架下的协同关系。论文进一步构建了OxfoLD数据集以支撑训练与评估,实验结果表明,TACO在定位和检测性能上均有显著提升。
该论文第一作者是厦门大学信息学院2023级博士生邢乐园、2025级硕士生张桓嘉,共同通讯作者是温程璐教授和王程教授,由潘东屿、毕业生吴海(鹏城实验室)、夏启明、熊恪峥、毕业生李文(布里斯托大学)共同合作完成。
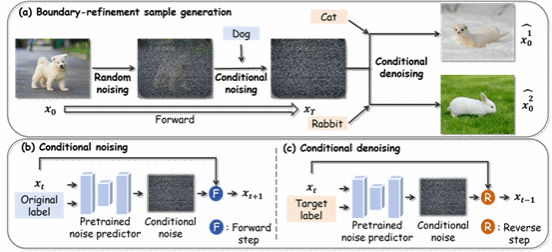
论文15:Decision Boundary-aware Generation for Long-tailed Learning
简介:长尾数据会使分类器的决策边界偏向头部类别,从而削弱尾部类别的识别精度。基于扩散模型的生成式数据增强方法通过生成额外样本来缓解这一问题。然而,我们发现,尽管头尾迁移有助于在整体上平衡分类器的决策空间,但同时也会引入潜在的非局部特征混合,使不同类别的特征发生纠缠,导致决策边界重叠以及尾部类别分布偏移。针对这一现象,我们首先明确提出了“边界模糊”问题,并进一步设计了决策边界感知生成(DBG)框架。该框架通过生成具有信息量的近边界样本,强化模型对决策边界附近表征的学习能力。DBG在重平衡长尾数据分布的同时,使决策空间更加可分离,从而提升长尾学习效果。在多个标准长尾基准数据集上的实验结果表明,DBG在降低类别间重叠的同时,稳定提升了尾部类别精度及整体准确率。
该论文的第一作者是厦门大学信息学院2025级博士生杨嘉诚,通讯作者是卢杨长聘副教授,由2024级硕士张瑞弛、2025级硕士尚驰凯、李梦柯(深圳大学)、尚心怡(UCL)、高俊龙助理教授以及张永岗(香港科技大学)共同合作完成。
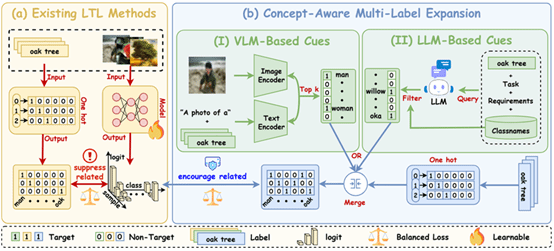
论文16:CUE: Concept-Aware Multi-Label Expansion to Mitigate Concept Confusion in Long-Tailed Learning
简介:在真实世界的识别任务中,数据通常呈现长尾分布,即少数头部类别样本充足而大量尾部类别样本稀缺。尽管近年来通过微调基础模型在长尾学习中取得了显著进展,但现有方法大多仅关注缓解类别分布不平衡带来的偏置问题,而忽视了由单标签监督互斥性引发的类别概念混淆现象,导致相关类别之间特征共享受限、头部类别主导效应增强,从而破坏类别间判别结构。针对这一问题,本文提出概念感知多标签扩展方法CUE,通过引入多标签概念信号以恢复类别间语义关系。具体而言,CUE结合零样本CLIP提取的实例级视觉线索与大语言模型生成的类别级语义线索构建概念集合,并分别通过加权的BLA辅助损失进行建模,与基础LA损失联合优化。实验结果表明,CUE在多个长尾基准数据集上实现了更加均衡且具有竞争力的整体性能,优于近期先进方法。
该论文共同第一作者是厦门大学信息学院2024级硕士生张瑞弛和2025级硕士生尚驰凯,通讯作者是卢杨长聘副教授,由2025级博士生杨嘉诚、李梦柯(深圳大学)、周阳(A*STAR)、高俊龙助理教授共同合作完成。